Ultra96にBNNをHLSで実装する方法
概要
FPT2021で実装したBNNの実装方法をメモしておきます.
実装内容
Vitis HLS 2020.2で高位合成によりBNN(二値化ニューラルネットワーク) IPを実装した.また,実装したIPをVivado 2020.2で論理合成と配置・配線を行い,ビットストリームを生成した.最後にUltra96内でビットストリームを読み込み,入力した画像がBNNにより検知が行われ出力が返ってくることを確認した.
使用したもの
- Ultra96-V2
- Vivado 2020.2
- Vitis HLS 2020.2
- PYNQ v2.5
BNN(Binarized Neural Networks)
BNNについて
BNNについての論文とその解説を以下に示す.
BNNは入力値や重みなど扱われる値が全て二値化されたニューラルネットワークである.BNNを使用する利点は重みを1と-1に二値化することで重みと入力値の乗算をXNOR回路で置き換えられるためである.すなわち,1をHigh(1),-1をLow(0)にマッピングすることで1と-1の乗算と同じ結果がXNOR回路で得られるようになり,演算の大幅な高速化が可能となる.よって,論理回路レベルで実装が可能なFPGAにおいて頻繁に使われる.
| x | w | wx | A | B | Z | |
|---|---|---|---|---|---|---|
| -1 | -1 | 1 | L | L | H | |
| -1 | 1 | -1 | L | H | L | |
| 1 | -1 | -1 | H | L | L | |
| 1 | 1 | 1 | H | H | H |
学習したBNN
今回はFPTで使用するために十字路と丁字路を検出するBNNを学習した.入力する画像は30x30ピクセルの画像であるため,入力層は900個のノードが存在する.中間層は1層でノード数は100個である.丁字路は向きによって下向き(down),左向き(left),右向き(right)に分けられるため,丁字路3種類と十字路(plus)と未検出(neg)を示す出力の計5つの値が出力となり,出力層のノード数は5つとなる.
高位合成
次に,高位合成によりBNNとスライディングウインドウを実装する方法を説明する.
作成したプログラム
作成したプログラムは以下の通りである.
https://www.togawa.cs.waseda.ac.jp/gitlab/fpt/bnn_hls
Synthesis Source Files
- sliding_window.cpp:axis interfaceから60x48個のデータを受け取り,30x30の大きさのスライディングウインドウで順にBNNによる検知を行い,その結果をaxisで返す.
- bnn.cpp:入力画像をbnn_layer1とbnn_layer2に通し,結果を返す.
- bnn_layer1.cpp:900個の入力を受け取り100個の出力を行う中間層における計算を行う.
- perceptron900.cpp:900個の入力と重み,1つのバイアスを受け取り計算結果を返す.
- bnn_layer2.cpp:100個の入力を受け取り5個の出力を行う出力層における計算を行う.
- perceptron100.cpp:100個の入力と重み,1つのバイアスを受け取り計算結果を返す.
- bnn_layer1.cpp:900個の入力を受け取り100個の出力を行う中間層における計算を行う.
- bnn.cpp:入力画像をbnn_layer1とbnn_layer2に通し,結果を返す.
TestBench Files
- sliding_window_tb.cpp:スライディングウインドウのシミュレーションに使うファイル.
- bnn_tb.cpp:BNNのシミュレーションに使うファイル.
- image.csv:30x30の画像の二値化データ
- image2.csv:60x48の画像の二値化データ
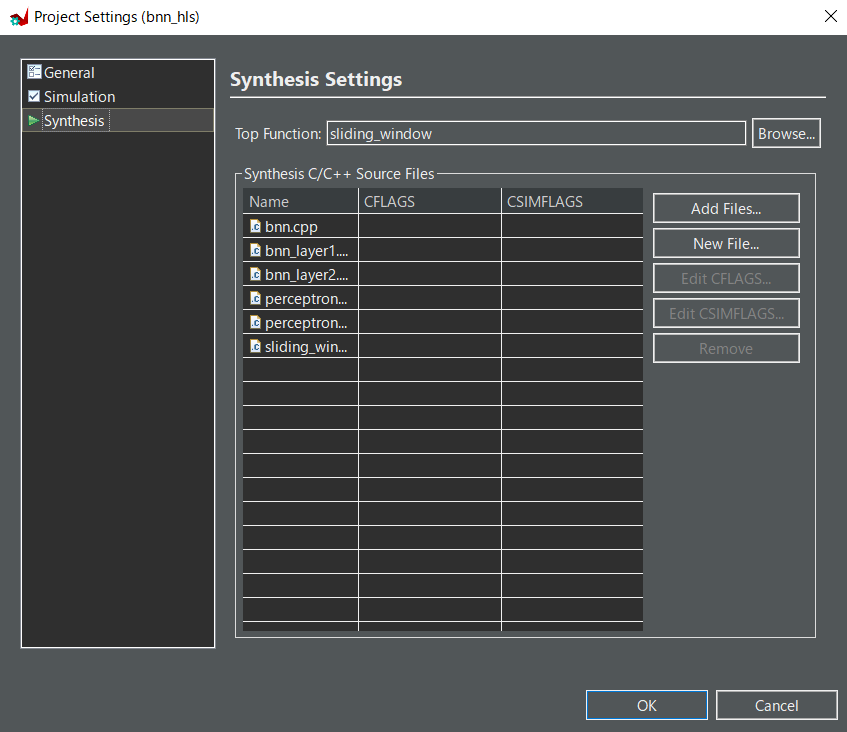
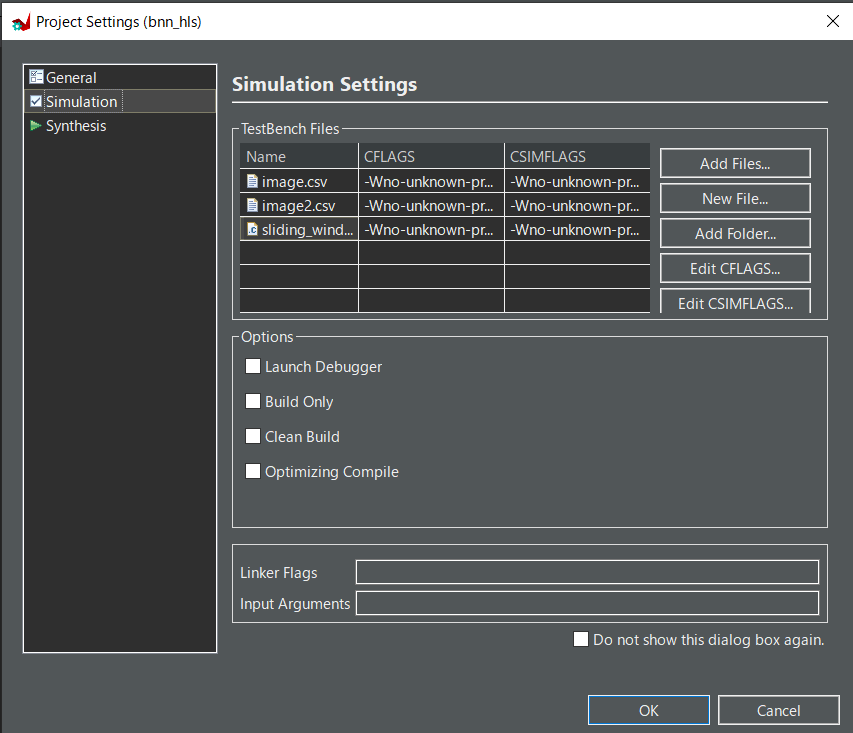
適当なプロジェクトを作成し,Project->Project Settingから以下の画像のようにプログラムを追加する.Top Functionはsliding_windowを選択する.Simulation Settingsにはbnn_tb.cppは追加しなくていよい.
※シミュレーションに使われるTest Bench Filesはmain関数をシミュレーション用の関数とするため,main関数が複数存在し衝突することを避けるためbnn_tb.cppは追加しない.
IPのエクスポート
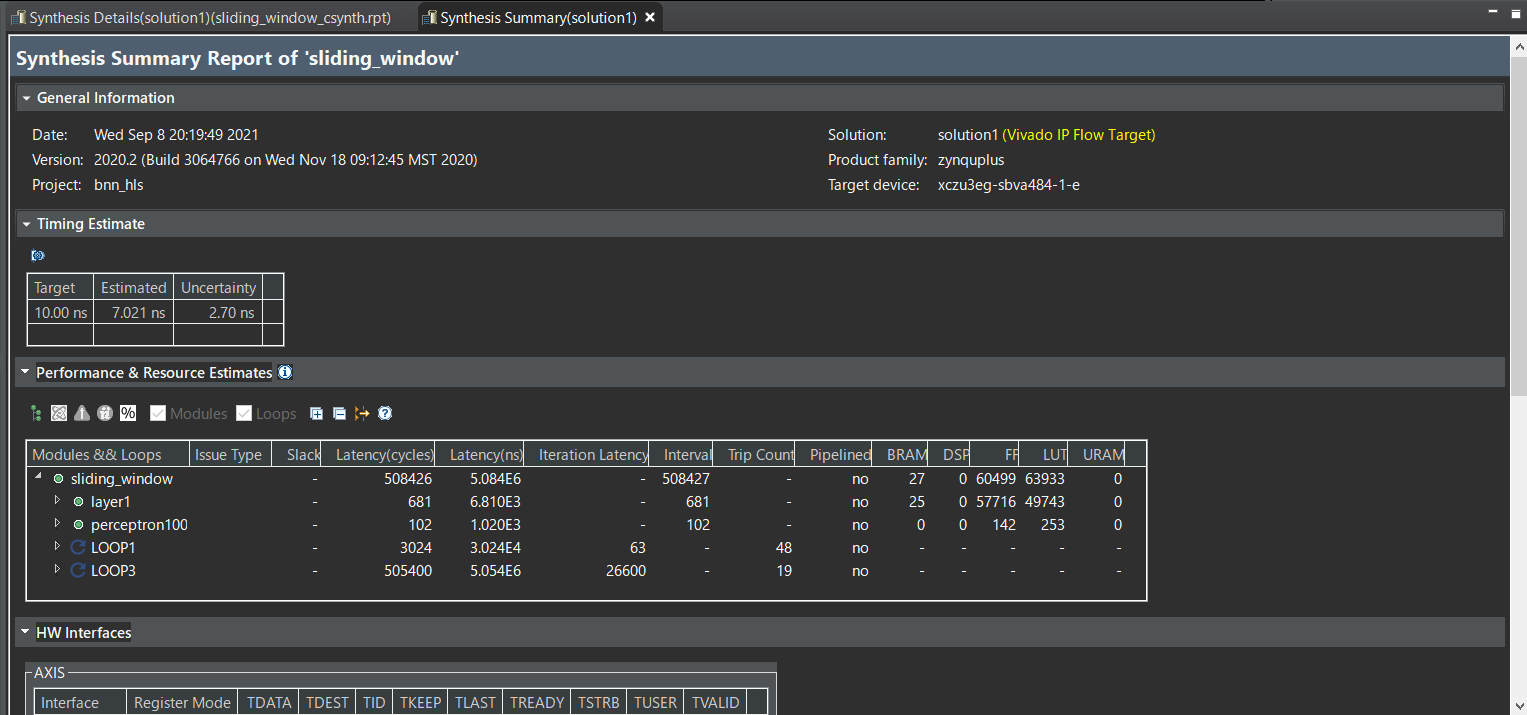
正しくファイルを追加した状態でC Synthesisを行うと高位合成が行われ,結果が出力される.以下のような画面が出力されれば成功.高位合成には数十分ほどかかる.高位合成が正しく行われたことを確認したらExport RTLからIPの生成を行う.
高位合成の高速化について
Vitis HLSではディレクティブを付与することによって高位合成の最適化ができる.この最適化は,IPが使用するリソース量と目指したい実行速度でトレードオフとなる.また,リソース量は使用するFPGAで使用できる量を超えないようにしなければならない.
ディレクティブで高速化を行う方法としては主に以下の2つがある.
- Pipeline...処理をズラしながら実行.例えば,図(B)において上段の
RDの処理は1サイクル目で終了するため,上段の処理の終了を待たずに下段のRDの実行を並列に始めることができる.![]()
- Unroll...全ての処理,またはいくつかの処理を同時に実行する.
![]()
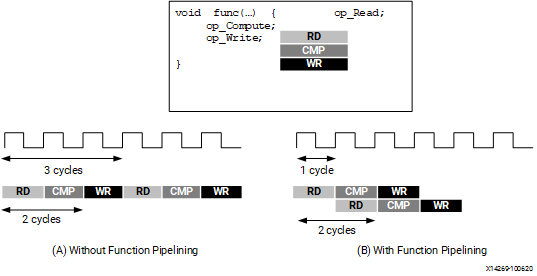

https://www.xilinx.com/html_docs/xilinx2021_1/vitis_doc/vitis_hls_optimization_techniques.htmlより引用
今回はbnn_layer1においてそれぞれのパーセプトロンの値の計算を高速化しようとした.通常Unrollの方が全てを同時に実行するため高速化できそうであるが,pipelineを指定したほうが実行速度が早く消費リソース量も小さかった.ディレクティブの指定による高速化はプログラムの書き方などにも関わってくると思われるため,このあたりは内部でどのように実装されているのかを解明した上で最適化できるようにしたい.
ディレクティブによる高位合成の最適化の詳細は以下を参照すること.
https://www.xilinx.com/html_docs/xilinx2021_1/vitis_doc/vitis_hls_optimization_techniques.html
論理合成と配置・配線
次に,作成したIPをVivadoで読み込み,配置・配線とビットストリームの生成を行う.
IPの読み込みとBlock Designの作成
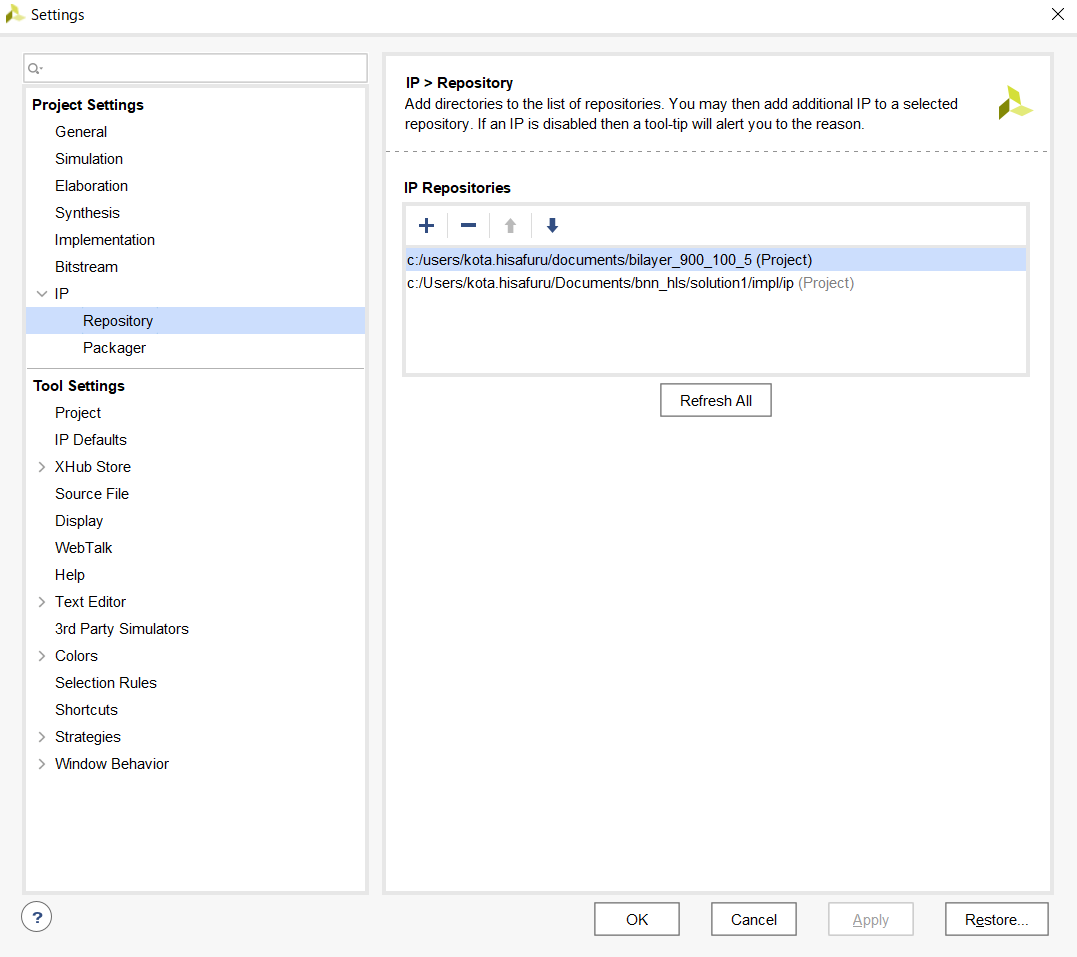
Vivadoでプロジェクトを作成したらTools->Settings->IP->Repositoryから+ボタンを押し,Vitis HLSで使用したプロジェクトファイル名/solution1/impl/ipを選択して生成したIPを追加する.
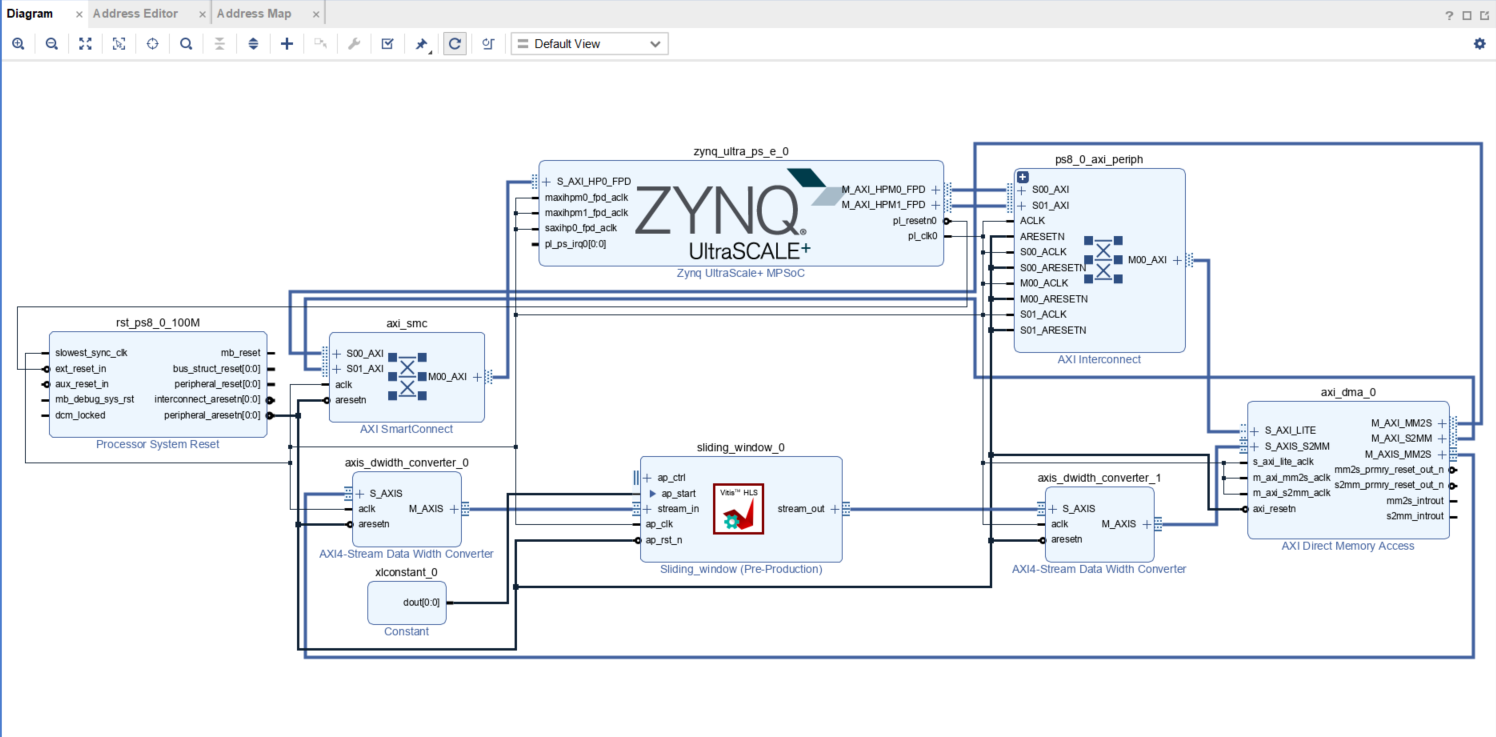
次に,Create Block Designより新規にBlock Designを生成し,以下のようにIPを配置する.
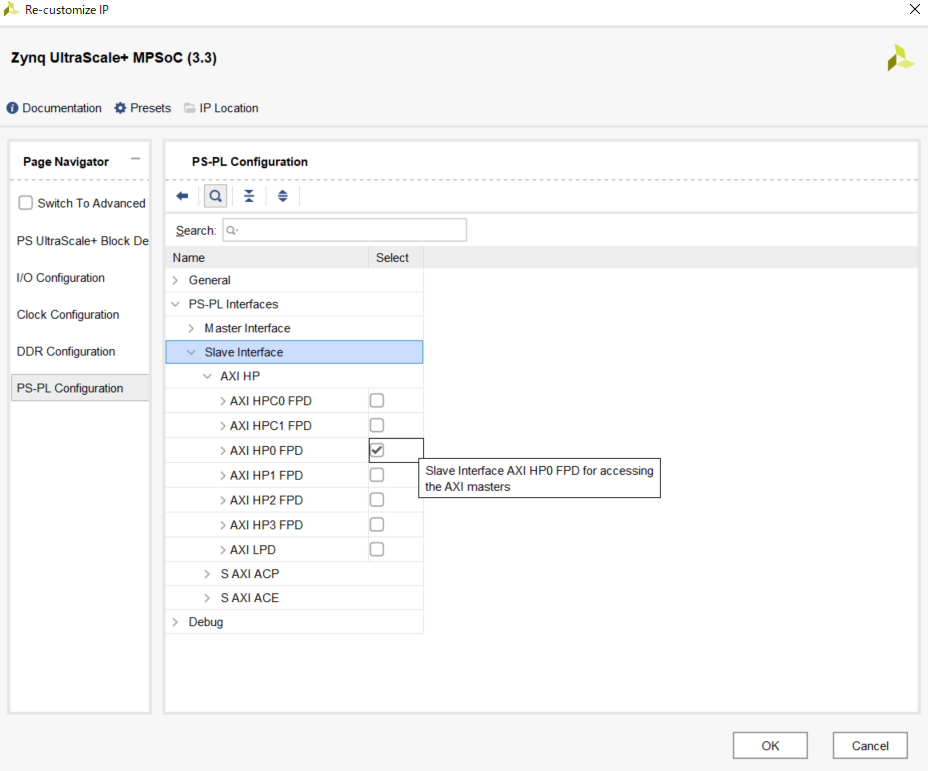
また,その際zynqの設定からHP0 portを有効化する.
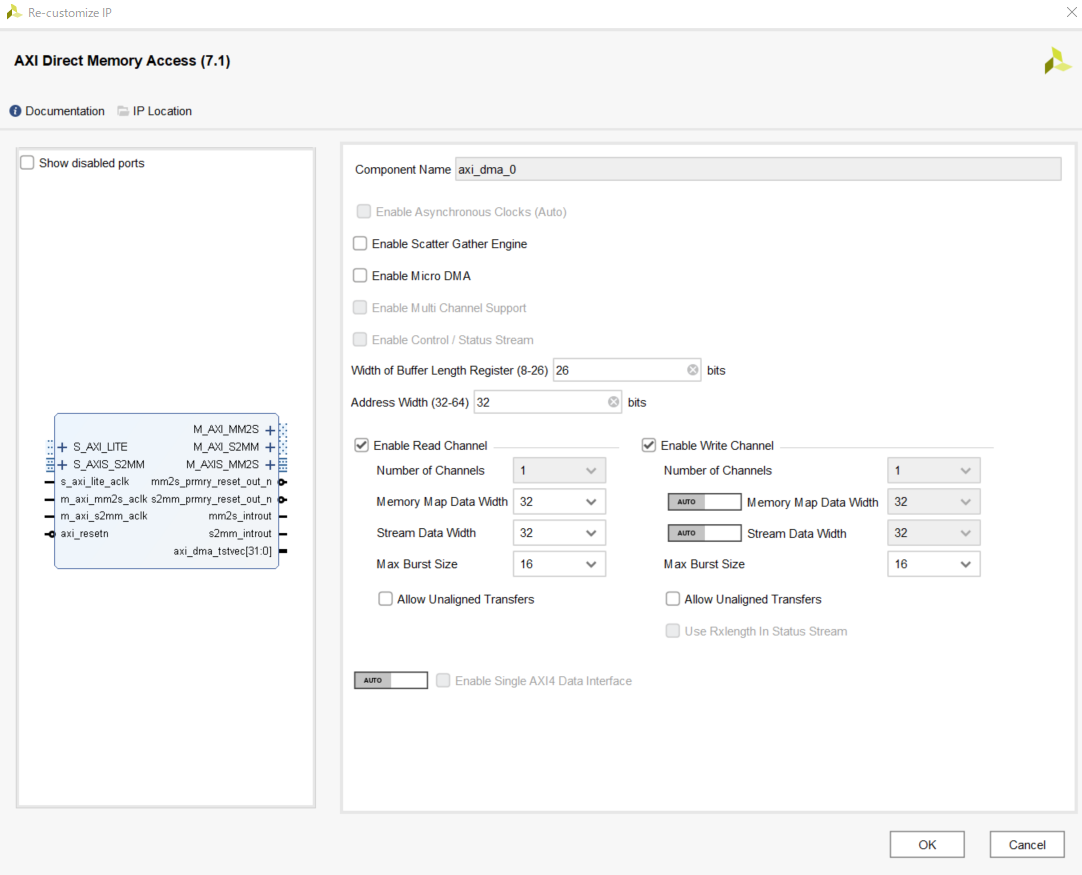
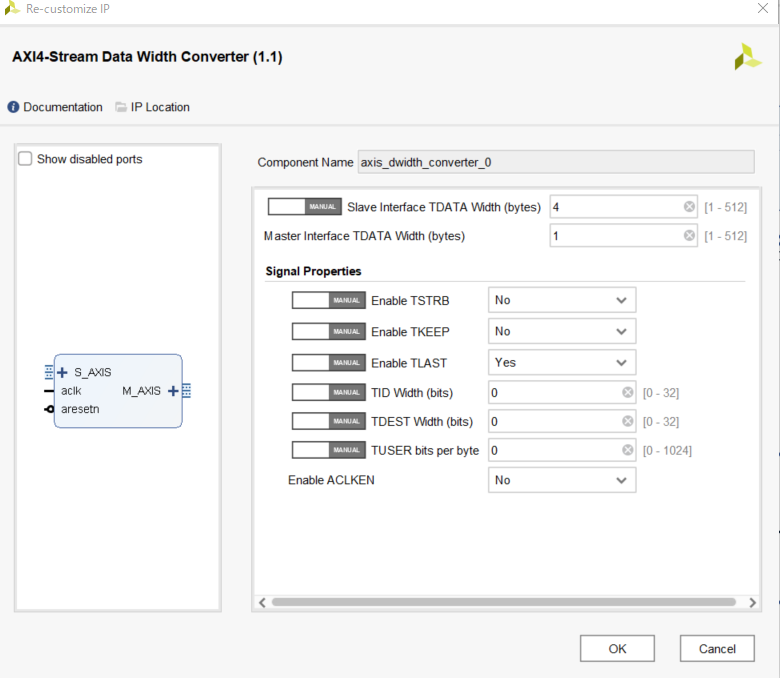
DMA,Data Widht Converterは以下の通り設定する.画像のData Widht Converterの設定はsliding_window_0に対し入力側のものなので,出力側ではSlave Interface TDATA Widthを1,Master Interface TDATA Widthを4にする.
設定が終わったらSourcesタブよりdesign_1_iを右クリック,Create HDL Wrapperからwrapperを生成する.その後,Run Synthesisから論理合成を行う.終了すると配置・配線を行うか聞かれるのでRun Implementationを実行.その後,Generate BitStreamでビットストリームの生成をして終了.
PYNQから実行
Ultra96v2にPYNQをインストールし実行,Jupyter Notebooksを開く.その後,適用なフォルダを作りそこに.bitファイルと.hwhファイルをアップロードする.アップロードするファイルの場所はvivadoのプロジェクトフォルダ名が仮にfpt_bnnである場合,以下のようになる.
- fpt_bnn/fpt_bnn.gen/source_1/bd/design_1/hw_handoff/desing_1.hwh
- fpt_bnn/fpt_bnn.runs/impl_1/design_1_wrapper.bit
design_1_wrapper.bitはdesign_1.bitに名前を変更しておくこと.Jupyterで実行するプログラムを以下に示す.out_bufferに出力が返ってくれば成功.
from PIL import Image
import numpy as np
from IPython.display import display
from pynq import Xlnk
from pynq import Overlay
import cv2
import time
HEIGHT = 48
WIDTH = 60
#dmaの設定
ip = Overlay("./design_1.bit")
dma = ip.axi_dma_0
#画像読み込み(画像は何でも良いです)
image_path = "../images/Sinsinawa_640_480.jpg"
original_image = Image.open(image_path)
original_image.load()
#画像の2値化
input_array = np.array(original_image)
input_array = cv2.cvtColor(input_array, cv2.COLOR_BGR2GRAY)
input_array = cv2.resize(input_array, dsize=(WIDTH, HEIGHT))
for i in range(HEIGHT):
for j in range(WIDTH):
if input_array[i][j] >= 127:
input_array[i][j] = 1
else:
input_array[i][j] = 0
input_image = Image.fromarray(input_array)
width, height = WIDTH, HEIGHT
print(width,height)
#dmaの入力と出力のバッファを確保
xlnk = Xlnk()
in_buffer = xlnk.cma_array(shape=(height,width), dtype=np.uint8, cacheable=1)
out_buffer = xlnk.cma_array(shape=(19*31,5), dtype=np.uint8, cacheable=1)
in_buffer[0:width*height] = input_array
buf_image = Image.fromarray(in_buffer)
#実行
def run():
dma.sendchannel.transfer(in_buffer)
dma.recvchannel.transfer(out_buffer)
dma.sendchannel.wait()
dma.recvchannel.wait()
start = time.time()
run()
elapsed_time = time.time() - start
print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")
print(out_buffer)
折りたたむ
おわりに
一から高位合成の説明をしていると長くなるのでだいぶ端折りました.わからない部分や詳細は久古まで直接聞いてください.