The Hardware/Software Cosynthesis Group in the Togawa Lab is researching the cosynthesis of hardware and software for processors with a set of instructions for a specific application. Currently, we are working on a hardware/software cosynthesis project called "Hardware/Software Cosynthesis System for Processors Having Packed SIMD Type Instructions, SPADES."
A processor refers to a semiconductor circuit that executes a prescribed set of data processing according to the instructions of an application program (application). Although not identical, think of a processor as an LSI. Almost everything that is used in daily life has an embedded processor. For example, an electronic device (e.g., cell phone or personal computer) requires extensive signal processing. One objective in designing a processor is to achieve a high processing speed while simultaneously realizing a small processor footprint.
Hardware refers to a mechanism comprised of dedicated computers that process and return a result upon an instruction for complex processing. Although processing by hardware is generally fast, the footprint of the processor itself is large.
Software refers to a mechanism where multiple computers, which can only execute simple operations, are used. Each computer executes processing upon instruction, but as a whole outputs the result for complex processing for a set of data. Software generally requires a smaller processor footprint, but the processing time is longer than that using hardware.
As mentioned above, hardware has a short processing time, but a large physical footprint, whereas the opposite is true for software. Different hardware-software combinations should result in processors with different structures. Hence, there is a trade-off between processing time and the footprint. Our hardware/software cosynthesis system aims to automatically generate a processor that is specialized for a specific application by determining the best combination of hardware and software under various constraints.
A packed SIMD type instruction uses one b-bit computing unit to execute n pieces of b/n-bit operations, where n represents the packing number. For example, using a 32-bit packed SIMD type computing unit enables four 8-bit operations to be executed simultaneously (4 packing operations), which means that the computation speed is four times faster than executing four 8-bit operations individually using regular 32-bit computers.
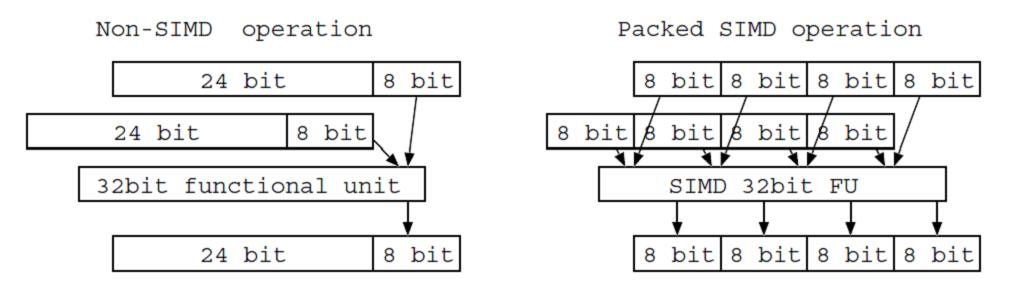
|
There are many kinds of packed SIMD type instructions. For example, some select the number of packings to be executed, while others determine whether to shift after an operation and if shifting, the direction and extent of the shift. The table below shows the kinds of operations that can be selected.
| Kind of operation | Addition, subtraction, multiplication, multiply-addition |
| Number of packings | 1, 2, 4 |
| Bit expansion | Bit expansion enabled/disabled, Selection of upper bit/lower bit operation |
| Sign bit | Selection between operation with or without sign bit |
| Shift | Shifted/not shifted, direction of shift (right or left), amount of shift (1 to 32) |
| Saturate operation | Saturate operation enabled/disabled |
Consider the case where both a multiplication instruction (MUL_4_ur4w) for “4 packings, no bit expansion, no sign bit, shift to the right by 4, no saturation operation” and an addition instruction (ADD_2h_ss) for “2 packings, with bit expansion, upper bit operation, with sign bit, no shift, with saturation operation” are possible. It may seem that for four parallel 8-bit operations, four 8-bit computers can be used in place a 32-bit computer. However, the packed SIMD type computer has a structure where four-packing and one-packing computations are both possible, allowing a 32-bit computer to be used when four parallel 8-bit computations are desired. Hence, the packed SIMD type computer can reduce the processor footprint.
Hardware-software cosynthesis systems require:
To perform the above tasks, our SPADES system consists of the following four processing systems:
A compiler analyzes an application described by the C language, which is an input file to the cosynthesis system, and produces assembly codes that can be executed at the fastest speed. The fastest executable assembly codes obtained by application analysis processing are outputted to the hardware and software division systems.
The hardware structure of the processor is determined based on the fastest executable assembly codes outputted from the compiler system upon considering the processor footprint and the application execution time. At the same time, the assembly codes are changed so that they can be executable in the obtained processor structure. The processor hardware structure and changed assembly codes are outputted to the hardware generation system and software generation system.
Hardware generation creates a HDL description of the processor based on the hardware structure of the outputted processor from the hardware/software division system. The HDL description of the outputted processor from the hardware generation system is one of the outputs from the entire cosynthesis system.
Software generation develops a software environment for the synthesized processor based on the outputted hardware structure of the processor and the altered assembly codes from the hardware/software division system. The software environment consists of a compiler, assembler, and simulator. The outputted software environment from the software generation system is one of outputs from the entire cosynthesis system.
The input and output to/from SPADES are as follows:
Input
Output
SPADES aims to generate an application-specific processor with the smallest footprint that satisfies the execution time constraint. For this reason, the input requires an application execution time constraint.
If a system is implemented with software, the memory must store a program describing the processing contents. Because the memory access speed is much slower than the processor speed, the processor ends up waiting for the data to be fetched from the memory, slowing the overall processing speed of the system.
To overcome this shortcoming and to reduce the access time, an idea was proposed to store only frequently-used data in a high-speed memory located close to (or inside) the processor. This is called a cache memory. Depending on how the data is stored, the cache memory can have one of three configurations:
None of these configurations is superior because the data access speed and probability of the desired data residing in the cache (i.e., the hit rate) varies. The direct mapping system may be well suited for application A, but the set associative system may be better for application B. In addition, the optimum cache capacity and line size (the amount of data that is brought out from a main memory at one time) vary by application. A memory with a large capacity occupies a lot of space, and its access speed is slow due to the large amount of data to be searched. Conversely, a memory with a small capacity has a small amount of data on a cache, reducing the hit rate. In addition, a large line size enables the simultaneous transfer of a large amount of data, but it takes time to fetch the data from the main memory. On the other hand, if the line size is small, multiple accesses may be required to recall the data.
Cache optimization analyzes an application to adjust between these factors and output an appropriate configuration. This improves the processing speed carried out by the software.